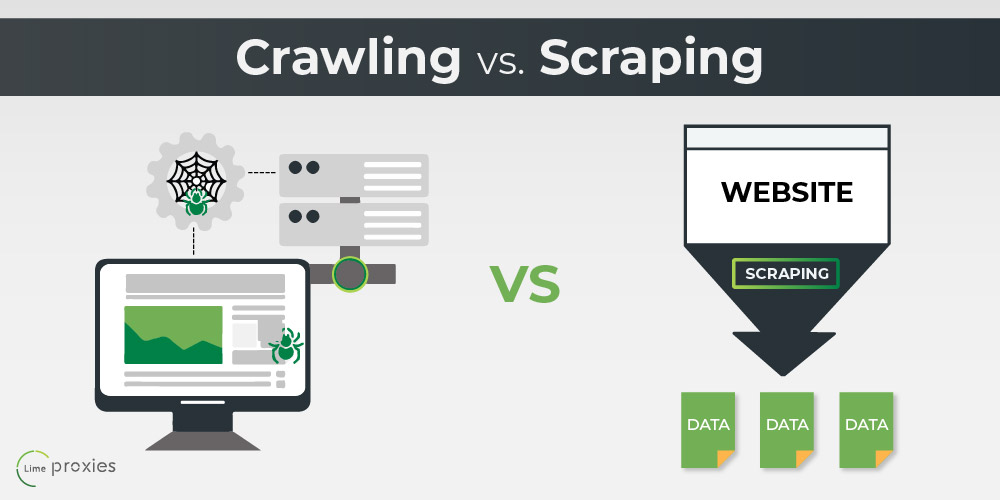
Information Crawling Vs Information Scratching https://website6082507.nicepage.io/?version=f3b4b78e-9fed-44d9-a874-5a446136bbd3 There is no straightforward response to the inquiry "is web scraping lawful? " as one have to answer whether the scuffing done does not breach any kind of laws surrounding the claimed data. Online search engine find and index your website based on algorithms that have really certain search parameters. A web designer and search engine optimization professionals should take care of the optimization procedure that would lead to expanding rankings and boosting web traffic, boosting your web site and, consequently, your organization. Collect real-time trip and resort data to and build a strong technique for your travel business. We can select either technique depending upon the nature of information we are searching for. Information scuffing and information crawling can be based on a selection of obstacles, such as lawful and ethical concerns, technological difficulties, and quality problems. It is necessary to value the information proprietor's civil liberties and permissions, and stay clear of any type of infractions of the legislation. Some pages or records may have vibrant, complex, or encrypted material that can make information scraping or creeping tough or impossible. To get rid of these obstacles, you might require to utilize sophisticated methods, such as browser automation, proxies, or APIs. In addition, some websites or papers may have unreliable, incomplete, or obsolete information that can affect the integrity and credibility of your outcomes. On the other hand, information crawlers are made use of in search engines to offer the needed search engine result. The high quality of the information obtained with internet scraping and internet crawling also differs. Internet scratching is often utilized to remove highly targeted and exact data from websites, as the data is especially targeted and the code made use of to remove it is normally extra complex. Web crawling, on the other hand, can frequently be done with easier code as it does not call for the exact same level of uniqueness in data extraction. This difference has important ramifications for the tools and strategies utilized in each process. Worldwide of data collection and analysis, 2 terms that you may have encountered are web scraping and web crawling. Both methods are utilized to extract details from websites, yet they http://waylonyewx921.cavandoragh.org/api-integration-services-to-drive-business-potential-customers stand out processes with one-of-a-kind features. Something you should know with internet crawlers is that some websites might not desire crawlers searching through their pages. Some websites will obstruct certain web spiders using a robots.txt file. This can avoid details crawling representatives from indexing a website's web pages, yet they do not protect against material from being indexed by search engines. Information scuffing, on the other hand, refers to the extraction of information from any type of resource. Most of the time, irrespective of the methods entailed, we https://app.gumroad.com/kurtmhansen880/p/5-major-obstacles-that-make-amazon-information-scraping-excruciating-datahut refer to the access of information from the site as scuffing. Not just do they browse through web pages, yet they additionally collect all the appropriate information and index it at the same time. There are numerous means to obtain details and information from the Net. The two most prominent ways are Information Crawling and Data Scraping as called. Both web crawling and data scraping are approaches of obtaining information and the details needed and procedures involved in gaining them.
- There are some vital distinctions in between scuffing and crawling.Anyway, most individuals describe the two as if they coincided point.We extract the data you need from any kind of site to satisfy all your service needs with 100% precision.If the web content of a website is easily visible by web spiders, they are likely to rank greater in search engine results because the content they have is less complicated to discover.Both methods are made use of to draw out info from internet sites, however they are distinct procedures with special qualities.
Microsoft Excel: Bring Data Together To Build Data-empowered Strategies
Data scratching, on the various other hand, doesn't necessarily entail data de-duplication. There are several means to acquire info or information from the web. Of those several methods, two of the most preferred ones are particularly web crawling and data scraping. Although you might typically listen to people making use of the terms nearly reciprocally, the truth is far from this false impression. There are some essential distinctions between scuffing and crawling. Not only do they check out pages, however they additionally gather all the appropriate info that indexes them at the same time. They additionally try to find all web links to the associated pages while doing so. Information scratching is necessary for a business, whether it is for the procurement of clients, or organization and profits development. Information scuffing solutions can carrying out actions that can not be accomplished by software program crawling devices. Things like javascript execution, submission of information styles, opposing robotics guidelines-- all are a point information scratching services can handle. In spite of all the differences, internet scuffing and internet crawling have specific imperfections.Data Scuffing Vs Information Crawling: Can You Incorporate These Two?
Information scraping is commonly utilized to remove details info for research or service functions. This strategy includes making use of internet crawlers or bots to navigate with different websites by accumulating details in the process. Spiders are automated software programs that creep via website to index new content. For companies that intend to grow in performance and superb company, it's necessary to implement right data monitoring. Likewise, keep mind that there are different information extraction techniques to choose too, from easy to advanced. JPEG styles are most usual information scuffing formats with a long tradition and assistance from every web browser and photo editor on the marketplace.Nvidia Hints At Replacing Rasterization and Ray Tracing With Full ... - Slashdot
Nvidia Hints At Replacing Rasterization and Ray Tracing With Full ....

Posted: Mon, 25 Sep 2023 07:00:00 GMT [source]